

Why it's wrong to frame ByteDance's 'piracy engine' as 'America good, China bad'
#92 | PLUS: Radio star claims Google stole his voice | Complainants deride Google's AIO assurances | Starmer gets tough on AI chatbots |✨AND: Is Meta set to spawn a new generation of 'glassholes'?


WELCOME TO Charting Gen AI, the global newsletter that keeps you informed on generative AI’s impacts on creators and human-made media, the ethics and behaviour of the AI companies, the future of copyright in the AI era, and the evolving AI policy landscape. Our coverage begins shortly. But first …
SPONSOR’S MESSAGE
Join global media leaders at Media Law International’s sixth Annual Global Conference, taking place in London on May 7 — and receive a 30% discount.

AGC6 offers cutting-edge thought leadership and superlative networking as it focuses on advancing commercial and legal solutions for the global media landscape. Previous participants include high-profile delegates from Kantar, Hanway Films, Paramount, Sony Music, Google, Havas Media Group, Alibaba Group, TVNZ, TVN, Ringier, Thomson Reuters, Dentons, Charles Russell Speechlys, Baker McKenzie, White & Case, WKB Lawyers, and Punuka Attorneys at Law. Past and returning speakers include general counsels from CNBC-e, the BBC, Channel 4, The Guardian, The Sun and Mediaspace.global.
BOOK HERE using the promo code G30 to receive your 30% discount.
LEAD STORY
© AI COPYRIGHT & LICENSING

CHINESE TECH giant ByteDance beat a retreat this week after its latest AI model provoked a furious Hollywood backlash and threats of legal action over mass copyright infringement.
This was the biggest row over intellectual property violation since OpenAI released its Sora app last year. As we say in our comment below, ByteDance appears to have borrowed from Sam Altman’s marketing playbook.
‘CINEMA AESTHETIC’
Last week the TikTok-owner unveiled video generator Seedance 2.0 boasting it delivered “a remarkable” quality leap with outputs “achieving unprecedented naturalness” and a “distinct cinematic aesthetic”.
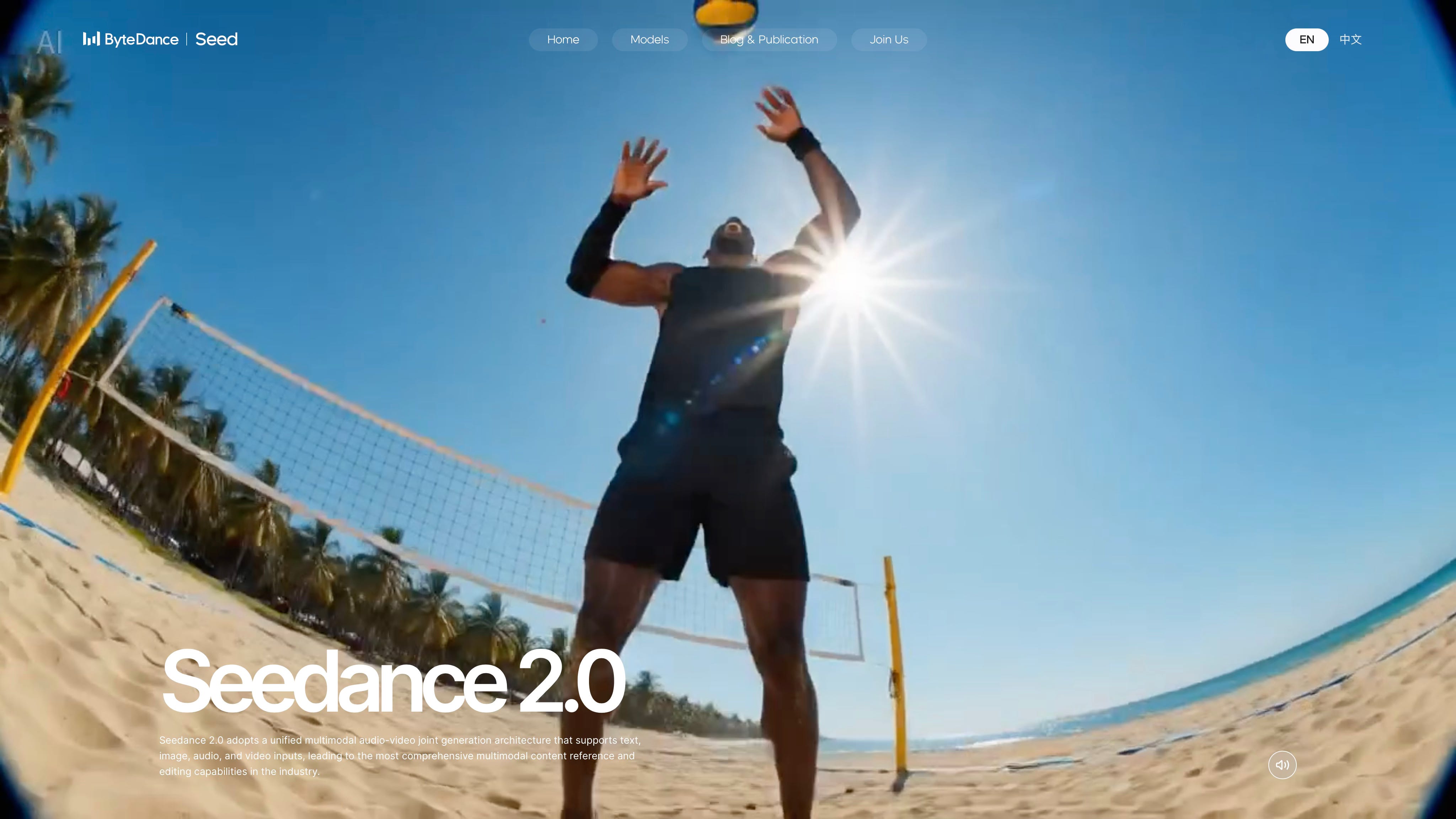
ByteDance didn’t say how the new model was trained, but clues soon became apparent in an output posted on X. That post rang alarm bells across Hollywood.
‘IT’S LIKELY OVER’
Filmmaker Ruairi Robinson shared a 15-second clip depicting Tom Cruise and Brad Pitt engaging in a fight sequence on a rooftop backed by dramatic orchestral music. Robinson said the hyper-realistic clip was the result of a two-line prompt.

Deadpool screenwriter Rhett Reese reposted it with a doom-laden comment:
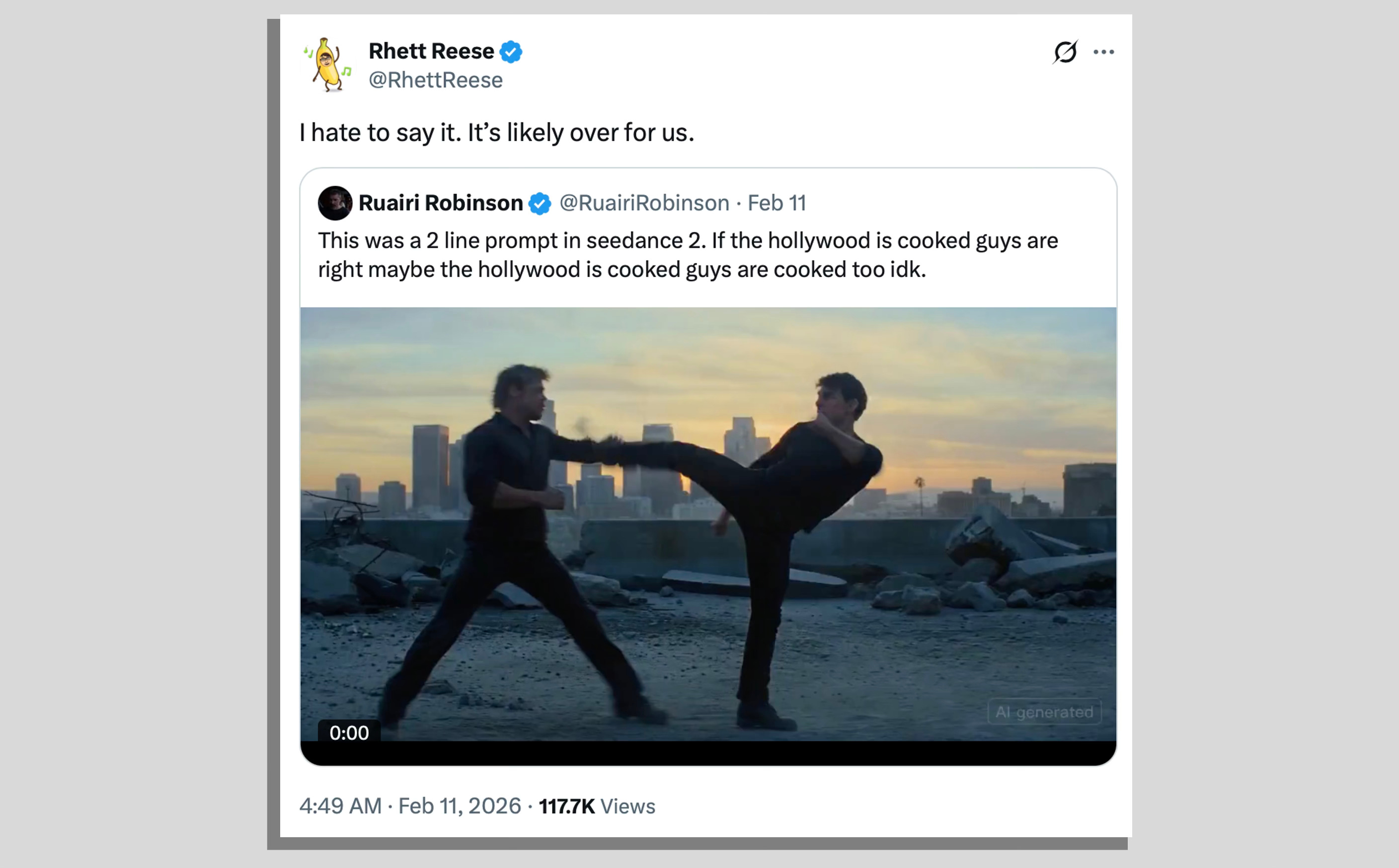
“I hate to say it. It’s likely over for us,” said Reese. “In next to no time, one person is going to be able to sit at a computer and create a movie indistinguishable from what Hollywood now releases. True, if that person is no good, it will suck. But if that person possesses Christopher Nolan’s talent and taste (and someone like that will rapidly come along), it will be tremendous,” he added. Soon other Seedance videos featuring characters from iconic movies began to flood social networks.
THE BACKLASH BEGINS
Charles Rivkin, chairman and CEO of the Motion Picture Association (MPA) rushed out a statement accusing ByteDance of violating creators’ copyright.

“In a single day, the Chinese AI service Seedance 2.0 has engaged in unauthorised use of US copyrighted works on a massive scale,” said Rivkin. “By launching a service that operates without meaningful safeguards against infringement, ByteDance is disregarding well-established copyright law that protects the rights of creators and underpins millions of American jobs. ByteDance should immediately cease its infringing activity.”
The Human Artistry Campaign, which fights for the responsible use of AI, declared Seedance 2.0 had attacked creators “around the world”. “Stealing human creators’ work in an attempt to replace them with AI generated slop is destructive to our culture: stealing isn’t innovation. Authorities should use every legal tool at their disposal to stop this wholesale theft.” SAG-AFTRA, the union representing 160,000 performers, writers and entertainment professionals, condemned the “blatant infringement” enabled by ByteDance’s new model.
“The infringement includes the unauthorised use of our members’ voices and likenesses. This is unacceptable and undercuts the ability of human talent to earn a livelihood. Seedance 2.0 disregards law, ethics, industry standards and basic principles of consent. Responsible AI development demands responsibility, and that is nonexistent here.”
STUDIOS REACT
In a cease-and-desist letter seen by Axios, the Walt Disney Company accused ByteDance of pre-packaging Seedance 2.0 “with a pirated library of Disney’s copyrighted characters from Star Wars, Marvel, and other Disney franchises, as if Disney’s coveted intellectual property were free public domain clip art.” Axios reported the letter further accused ByteDance of “hijacking” its characters “by reproducing, distributing, and creating derivative works” that featured them.
“ByteDance’s virtual smash-and-grab of Disney’s IP is wilful, pervasive, and totally unacceptable. We believe this is just the tip of the iceberg — which is shocking considering Seedance has only been available for a few days.”
Netflix’s cease-and-desist letter, seen by Variety, branded the model “a high-speed piracy engine, generating mass quantities of unauthorised derivative works utilising Netflix’s iconic characters, worlds, and scripted narratives”. “Netflix will not stand by and watch ByteDance treat our valued IP as free, public domain clip art.” Variety also obtained a similar letter from Paramount Skydance which demanded ByteDance “immediately take all necessary steps” to prevent violations of its IP rights and “remove all infringing instances of Paramount’s content from ByteDance’s platforms and systems”.
JAPAN INVESTIGATES
Included in the plethora of Seedance 2.0 clips were those featuring Japanese manga and anime characters. According to the South China Morning Post the violation prompted an investigation by Japan’s cabinet office with the nation’s AI minister Kimi Onoda telling a press conference: “We cannot overlook a situation in which content is being used without the copyright holder’s permission.”
BYTEDANCE BACKS DOWN
Having provoked the ire of Hollywood and taunted the global creative industry ByteDance then relented. In a statement the social media giant and AI developer told the BBC it respected “intellectual property rights and we have heard the concerns regarding Seedance 2.0”. The statement went on: “We are taking steps to strengthen current safeguards as we work to prevent the unauthorised use of intellectual property and likeness by users.” Details on how those safeguards might work were not provided.
📣 COMMENT: Coverage of ByteDance’s flagrant violation of rightsholders’ intellectual property was framed as the latest skirmish in the ‘AI wars’ being fought between the US and China. Yes, by training its hyper-realistic video model on studios’ content and allowing near-identical outputs of their most valuable and iconic content ByteDance parked its tanks on the Hollywood skyline. But before the Trump admin gets on its ‘America AI First’ high horse it might first want to look in its own backyard. Last year OpenAI’s video app Sora allowed users to generate videos featuring copyrighted characters, and sure enough soon after that launch videos styled on protected Hollywood content flooded social networks. Just before the launch OpenAI informed talent agencies and studios that its TikTok-style app would feature their works. If they objected then they would need to alert OpenAI by reporting individual violations rather than seeking a blanket opt-out. In the furore that followed OpenAI CEO Sam Altman blogged that after “taking feedback” — presumably from furious rightsholders who had contacted him — OpenAI would move to an opt-in model. But the damage had been done. And the Sora app rocketed to the top of the download charts. ByteDance appears to have learned from OpenAI’s marketing playbook: flood the zone with infringing content, generate global headlines and free media coverage, then beg forgiveness. ByteDance’s egregious behaviour is no worse than OpenAI’s misconduct. It’s clearly done what BigTech has, and continues to do: train its models on rightsholders’ content scraped from the web and obtained from pirated datasets. So please, no ‘America good, China bad’ comments on this. They’re all in the wrong.
RELATED:



PLUS:
➡ Movie sales firm The Mise En Scene urges ‘No AI Used’ industry label
➡ Sony Group develops tech that can spot music used to generate AI songs
➡ Spotify sees opportunity for artists from derivative AI-generated remixes
➡ Law prof maps all 81 AI copyright lawsuits currently before US courts
➡ Munich court rules that three AI-generated logos are not copyrightable

ALSO THIS WEEK
🎨 AI & CREATIVITY

FOR EIGHT years he was the instantly recognisable voice of NPR (UK readers, think BBC Radio 4). Now radio host David Greene is suing Google saying the hi-tech trained its AI podcast platform on his dulcet delivery — without permission or offer of payment. Greene, who hosted NPR’s flagship show Morning Edition, told The Washington Post he “completely freaked out” when he heard Google’s NotebookLM — which features two virtual hosts engaging in light banter — since the male speaker sounded just like him. “It’s this eerie moment where you feel like you’re listening to yourself,” Greene told the Post’s Will Oremus.
You can judge the similarity for yourself. Here’s a short clip from a NotebookLM output generated by Charting featuring its male voice:
And here’s Greene talking about becoming the interim publisher of a news org:
This week Greene — who also hosts several podcasts — went on Morning Edition as a guest. He said he first heard NotebookLM’s male voice in 2024 after friends alerted him. “It’s not just the voice,” he said. “It was just those little phrases and little ways to emphasise words in a sentence and put a sentence together, put a question together. I think that was a real big part of it as well that just felt creepy.” His lawsuit has been filed in a Californian state court. Asked why he was suing, Greene said he felt compelled to act — both for himself, and others.

“I feel like I’m fighting for many of us in this industry,” said Greene. “I mean, I look back on my career, and the number of people who, sometimes in their darkest, most painful moments, talked to me in a war zone or after a disaster — like a terrible fire that destroyed their community — they were willing to sit with me and talk about it.
“The only tool that I felt like I brought into the room was myself, you know, expressing empathy, curiosity, respect with my voice. And just the idea that that can somehow be stolen is something that I couldn’t live with if I didn’t at least see where the courts could take this.”
Google said Greene’s allegations were “baseless”. Spokesperson José Castañeda told Gizmodo the sound of the male voice was “based on a paid professional actor” that Google had hired. Reacting, Greene told NPR: “I’m going to leave that to my lawyers and let them respond to whatever Google wants to say about this.”

Dr Mathilde Pavis, a leading expert in digital replicas, told Charting it wasn’t uncommon “for voice professionals to receive messages from people saying they’ve just heard them on a new product release, only to discover that it is in fact an AI-generated voice”. Asked what legal avenues were open to Greene, Pavis — legal counsel for OpenOrigins, the deepfake detection specialist, and legal adviser to performers’ union Equity — said: “The answer depends heavily on jurisdiction, but broadly speaking, voice cloning cases can activate several areas of law. Intellectual property (IP) rights may come into play in the form of performers’ rights, and occasionally copyright. But those typically require that the person’s actual recordings or performance have been used. Data protection law can also be relevant, because voice data is at least personal data and often biometric data when processed for voice modelling.
“If we take Google’s position at face value — that they did not use Greene’s recordings and instead hired another actor — then IP and data protection claims become much harder to pursue. Those areas of law require use of the actual recording or performance, not mere similarity. What remains then are claims based on imitation: certain types of personality rights, false endorsement, passing off, unfair competition leading to consumer confusion. In England, where we don’t have personality rights, we would speak of ‘goodwill’, best described as the ‘brand power’ or ‘attractive force’ attached to a name, persona, or voice.
“That area of law is far more piecemeal. It varies significantly across US states and globally. It is more difficult to access and often requires showing that consumers are likely to believe the person is endorsing or associated with the product. For many voice professionals, that is a high bar because they are not household names. Consumers may recognise the sound but not the individual. Greene’s position could be somewhat different given his career as a radio host. His voice, name, and style may be recognisable within his market, particularly among listeners familiar with his broadcasts. That could strengthen a confusion-based argument but it is still not straightforward.”
Pavis added that “ultimately, if no recordings were used, the case shifts away from cloning and into the much more complex and uneven terrain of imitation and reputation-based claims”. “That is possible to pursue, but it is legally narrower and fact-specific.”
🌟 KEY TAKEAWAY: Pavis speculated how Google could end up with a flagship voice product that sounds like Greene “and yet, as Google says, it is the result of collaborating with a completely different voice artist”. One explanation was that different voiceover markets and sectors tended to “favour particular vocal textures and performance styles”. “There are fashions, conventions, trends,” Pavis explained. “Certain tonal qualities are perceived as trustworthy, warm, authoritative, intelligent. Brands often brief towards those qualities. That can lead to convergence. So it’s plausible that Greene and the unnamed voice actor are both operating within a similar vocal genre (similar texture, similar cadence, similar stylistic positioning) and that is where the resemblance comes from. Not because one is the other, but because both are indexing the same set of vocal attributes that are currently valued in that space.”
RELATED:

PLUS:
➡ Asked how music model Lyria 3 was trained, Google exec doesn’t answer
➡ ElevenLabs recreates the voice of folk group singer diagnosed with MND
➡ Variety says upcoming movie Killing Satoshi to make extensive use of AI
➡ Ad industry chief proposes eight principles for the responsible use of AI

📰 AI & NEWS MEDIA
ORGANISATIONS THAT prompted the UK’s competition watchdog to investigate the “serious irreparable harm” being caused by Google’s AI search summaries have poured scorn on the hi-tech’s assurance it is exploring solutions.
Last week Google said it was in listening mode on the way its AI Overviews operate following last year’s landmark complaint to the Competition and Markets Authority (CMA) by justice non-profit Foxglove, the Independent Publishers Alliance, and the Movement for an Open Web (Charting #61). Their complaint — which was also lodged with the European Commission — claimed Google was abusing its dominant position by using publishers’ copyrighted content to power AI summaries which then directly competed with them. Last month the CMA proposed publishers should be able to stop their material being used in AI Overviews while remaining within traditional search (Charting #89).
Last week Google news partnerships chief Sulina Connal told an FT Strategies conference it had “heard the need for more controls” on how news content appeared in search. Press Gazette further reported Connal saying Google was planning “more granular controls”.
“Because AI is integral to how search works, implementing the new controls is a complex engineering, huge engineering project, and we have been highly intentional in our approach. The idea is to focus on simple, scalable tools that you can use to manage your content.”
Connal added: “We hear you, and we hear you loud and clear.” Reacting to Connal’s comments, Foxglove comms chief Tom Hegarty told Charting: “Frankly, Google can spin this however it likes: the reality is AI Overviews continue to inflict horrific damage on independent news publishers by stealing the news and choking off traffic to their reporting. That won’t stop unless and until journalists get a meaningful opt-out from AI Overviews — without also being chucked out of Google’s 90% monopoly of the global search market.

“Naturally, Google has launched an ostentatious PR exercise against being forced to halt its mass global theft of journalism, publicly hemming and hawing about the ‘huge engineering project’ supposedly required. But it is hard to feel much sympathy: Google is one of the world’s wealthiest companies, it has unimaginable resources. Meanwhile, every day seems to bring reports of another newsroom haemorrhaging reporters. Is it truly so hard for Google to stop stealing other people’s work, and pay them for it instead?
“No-one — least of all the CMA — should ease up on the pressure until the necessary action is taken and, crucially, done in a way that can be independently verified. I think we have all learned by now Google cannot be trusted to mark its own homework.”

Chris Dicker, CEO at CANDR Media Group and a board member of the Independent Publishers Alliance, told Charting: “The cynic in me thinks Google’s huge engineering project claim is a delay tactic. It had the choice to give publishers control from the start, yet during last year’s Department of Justice trial in the US we saw Google had decided not to do so in fear of too many people opting out.” Dicker said he was “optimistic” that a CMA-forced opt-out was in sight, “but I also unfortunately feel that it will be far too late by the time Google rolls it out”. Dicker added: “If AI Overviews become the default search experience, which seems to be the way Google is pushing it, then publishers won’t really have a choice.”
Tim Cowan, co-founder of the Movement for an Open Web and anti-trust chair at telecoms, media and technology-focused law firm Preiskel, told Charting: “Google has a long record of over-promising and under-delivering. To such an extent that the fines against it in France are approaching €1 billion (£873 million, $1.18 billion) and are over €10 billion (£8.73 billion, $11.8 billion) at EU level.”
▪️Meanwhile, the Financial Times said it was the lastest publisher to join Google’s AI pilot programme, first announced in December (Charting #84).
▪️And Penske Media Corporation (PMC) — which is suing Google over AI Overviews (Charting #72) — hit back at a motion to dismiss. In a court filing the Rolling Stone publisher said Google had “shattered the longstanding bargain that allows the open internet to exist” leaving publishers “with no choice: acquiesce — even as Google cannibalises the traffic publishers rely on — or perish”.
📣 COMMENT: Last month Google policy chief Roxanne Carter defiantly told UK lawmakers the hi-tech had no intention of paying for the content it scrapes from the web to train its generative models. “When it comes to training AI models on freely available content that is available on the open web, we do not believe that we should licence that content,” said Carter. Carter was pressed on whether publishers could remain in search but opt out of AI Overviews, but declined to answer while the CMA was deliberating (Charting #87). Back then Charting commented that the UK upper house’s Communications and Digital Committee should recall its witness and seek an explanation over her erroneous assertion that “freely available content” was free to take. Now that the CMA has spoken — albeit in the form of launching a consultation, followed by a period of consideration that could last a year — peers conducting their inquiry into AI and copyright should now also question Carter on Google’s plans to give publishers “more granular controls”. Will those controls actually enable them to opt out of AI Overviews, but remain in search? If so, when? If not, why not? And picking up on Hegarty’s point, might publishers who choose to allow their content to be used in AI summaries actually be paid? Again, if not, why not?
RELATED:

PLUS:
➡ Editor at Condé Nast’s Ars Technica says sorry for AI-generated quotes
➡ News org Mediahuis unveils pilot use of AI to automate ‘first-line’ news
➡ Future SEO chief shares AI search optimisation plan with Press Gazette
➡ The Guardian embarks on a year-long reporting project on AI and work
➡ San Francisco Standard wins major grant for news app with AI features

🏛️ AI POLICY & REGULATION

ONLINE SAFETY campaigners have welcomed UK moves to tighten rules on AI chatbots in the wake of the Grok scandal. Prime minister Sir Keir Starmer announced a series of measures aimed at closing loopholes in the Online Safety Act (OSA). Last month Starmer said his government “would not stand” for the “absolutely disgusting and shameful” actions of Elon Musk’s social media platform X and its built-in chatbot Grok which allowed the generation and sharing of non-consensual intimate images of women and children.
This week Starmer said actions taken on Grok — which include making it a criminal offence to create or request intimate images — sent a “clear message that no platform gets a free pass”, and that loopholes would be closed “that put children at risk”. The Online Safety Network — a coalition of organisations calling for tougher rules — said it was “pleased to see proposed measures to ensure AI chatbots are included in the OSA” but repeated its call that tech platforms should be forced to “undertake and act on their risk assessments before they release products to market”.
The Center for Countering Digital Hate — which seeks to protect human rights and civil liberties online — said UK law was “finally catching up with AI harms”. The move to close loopholes in the OSA was a “big step” towards safer digital spaces, but the organisation urged ministers to address remaining loopholes. “Only then can we truly hold tech platforms accountable for online harms.”
Clare McGlynn, professor of law at Durham University and a leading expert on violence against women and girls, said plans to regulate AI chatbots were “welcome” but stressed “it’s not just children who are affected”.

“Chatbots are intensifying violence against women and girls, and generating new ways to perpetrate and normalise abuse, as my current research project with colleagues is finding,” said McGlynn, who will report next month.
“We’re finding troubling ways in which chatbots are intensifying violence against women and girls and enabling new ways to perpetrate abuse, and significant legal gaps.”
McGlynn added: “We knew about deepfakes in 2017, but did nothing until it was pretty much too late. Let’s not make the same mistakes about chatbots.”
▪️Meanwhile, Ireland’s data protection watchdog said it had launched a “large-scale inquiry” into Grok’s “apparent creation, and publication on the X platform, of potentially harmful, non-consensual intimate and/or sexualised images” containing or involving the use of Europeans’ personal data. The Data Protection Commission (DPC) — which enforces Europe’s General Data Protection Regulation (GDPR) — said the probe would examine whether X had complied with data processing obligations and had conducted an impact assessment.
▪️And in Spain, prosecutors began an investigation into whether X, Meta and TikTok had spread child sexual abuse material (CSAM) online. On X prime minister Pedro Sánchez accused the platforms of “attacking the mental health, dignity and rights of our sons and daughters”. “The State cannot allow it,” Sánchez stressed. “The impunity of the giants must end.”
📣 COMMENT: In a related move the UK government also said it would force platforms to remove intimate images shared without consent within 48 hours of them being flagged. The move brings intimate image abuse content into line with CSAM and terrorist material. Firms refusing or failing to take down abusive imagery face fines of up to 10% of their global turnover, and having services blocked. Starmer said tech platforms were “already under that duty when it comes to terrorist material so it can be done”, and added that “we need to pursue this with the same vigour”. Strange then why the government is allowing social networks 48 hours to deal with abusive content. In a press release, UK tech secretary Liz Kendall said “no woman” should have to wait “days for an image to come down”. By our calculation 48 hours is two days. In India the take-down window is about to be shortened to just three hours. Giving social platforms 48 hours to erase intimate images shared without consent is a tacit acceptance that real-time moderation has been scrapped. Why pander to the platforms? Insist they introduce effective real-time moderation. And shorten the removal window.
RELATED:



PLUS:
➡ Axios reports on Democrats who are making AI focus of 2026 campaigns
➡ White House strongly opposes Utah Republican leadership’s state AI bill
➡ Anthropic’s Pentagon row escalates over terms military can use Claude
➡ Musk’s X seeks to sidestep Brazil’s Grok probe but lawmakers push back
➡ Bipartisan bill seeks to stop AI datacentres from driving up energy costs
➡ Unesco report predicts plunging incomes for musicians and AV creators
➡ Dutch data watchdog warns gen AI risks becoming regulatory Wild West

🧭 ELSEWHERE
▪️Answer engine Perplexity abandons advertising on user trust grounds
▪️Google says ads within its AI-powered search will ‘reinvent advertising’
▪️Study: a reliance on AI causes humans to ‘hallucinate with AI services’
▪️Musk brands Anthropic ‘misanthropic and evil’ with an anti-male bias
▪️Groundbreaking US court ruling says AI detection tools are unreliable
▪️KPMG Australia staff found to have used AI to cheat on internal exams
▪️Nature probes a ‘crisis’ in computer science research caused by AI slop
▪️Energy analyst: AIs are guilty of ‘diversionary’ tactics and ‘greenwashing’
▪️Sky News explains why you should never use AI to suggest a password
💬 QUOTES OF THE WEEK
“No one can tell you exactly when Trump’s time as president will be up. But nobody should forget what [OpenAI president Greg] Brockman and the like did during this time. If those who have funded Trump’s reign of terror are allowed to just wake up in a post-Trump world and pretend like it never happened, we’ll have failed as a society.” — Matt Novak, staff reporter at Gizmodo writing on Brockman’s attempt to defend a $25 million payment to a pro-Trump super PAC and another $25 million to a super PAC supporting pro-AI candidates
“Aardman in Concert is a quiet reminder that craft endures. Not because people are sentimental about it, but because it offers something that the slick, the algorithmic, and the instantly generated simply cannot: the evidence of a human hand. A thumbprint in the plasticine. An orchestra breathing together in a dark room. The irreplaceable warmth of something that somebody actually made.” — Journalist Tom May writing in Creative Boom on Wallace and Gromit studio Aardman Animations’ 50th anniversary tour with a full live orchestra
“It does feel like we are fucking doomed when that shit happens. It’s like, what do you do about that? This ship has, like, well and truly sailed. I mean, it is totally wack to be able to train the algorithm on artists’ work. Totally wack. Like totally cooked. Totally fucking horrible.” — Stu Mackenzie, frontman of Australian band King Gizzard & the Lizard Wizard, talking to The Atlantic’s Charlie Warzel on people using LLMs to generate copycat tracks on Spotify

✨ AND FINALLY …

BACK IN THE early 2010s a term was coined to describe socially obnoxious users of Google’s smart glasses. ‘Glassholes’ earned the derogatory label after sneakily recording videos of people in public places. Google was so concerned about a Google Glass backlash that it published official advice on how to avoid appearing creepy. “Standing alone in the corner of a room and staring at people while recording them through Glass is not going to win you any friends,” it opined.
More than a decade later another hi-tech is about to enable a new generation of glassholes as it adds the AI-powered feature it’s been sitting on for years: facial recognition. In 2024, three years after Meta launched its Ray-Ban smart glasses, two Harvard University students showed just how invasive the technology could be. In a video on X that soon went viral, AnhPhu Nguyen and Caine Ardayfio explained how they had hacked Meta’s specs and fooled strangers into believing they had met them before, thanks to widely available systems that detected faces in livestreams and pulled personal data from the web:

Nguyen and Ardayfio’s chilling demonstration — which was designed to reveal how easy it had been to add facial recognition to Meta Ray-Bans, and let people know how they could make themselves unsearchable — was dismissed by a Meta spokesperson who stressed its glasses couldn’t recognise faces. The decision to launch Meta Ray-Bans without facial detection followed a detailed consideration of privacy issues and a staffer in a company meeting highlighting the risk of “real-world harm”, including “stalkers”.
Meta now appears to have brushed aside those qualms. The New York Times this week reported that Meta is set to add facial detection “as soon as this year”. Tech journalists Kashmir Hill, Kalley Huang and Mike Isaac said staffers had told them the feature — known internally as ‘Name Tag’ — would allow users to “identify people and get information about them via Meta’s artificial intelligence assistant”. In a further sign of just how far to the dark side Meta has positioned itself in the Trump 2.0 era, a memo seen by the Times said the company would shield the launch by using a moment of political unrest as a distraction.
It’s hard to read the extract without visualising a James Bond villain pondering when to unleash a terrifying new weapon on an unsuspecting world:
“We will launch during a dynamic political environment where many civil society groups that we would expect to attack us would have their resources focused on other concerns.”
The Times said Meta was exploring who should be recognisable — just those that users are connected to, or everyone with a public account on a Meta platform. A Meta spokesperson was quoted as saying that while the company frequently heard there was “interest in this type of feature” it was “still thinking through options and will take a thoughtful approach if and before we roll anything out”.
But there is no thoughtful approach to a technology that would strip everyone of their privacy wherever and whenever they are encountered by a glasshole wearing souped-up Meta specs. To pretend otherwise would be like saying Zuckerberg was making a valuable contribution to society by unveiling FaceMash, his infantile ‘hot or not’ precursor to Facebook, or that his other privacy violations had been trivial errors. Let’s be absolutely clear: Meta Ray-Bans with facial recognition will cause immense harm, and prompt a massive privacy scandal. Lawmakers and regulators have the opportunity to prevent it. They must act.



One more time: Thank you!
Also, it’s nice to see big dogs going after AI cheats. When will small indie publishers like mine find representation and defense? I guess I can only hope that the big dogs bankrupt the AI cheats.